




First of all, setup your AWS account – and login into AWS Management Console. Then create any bucket you want.
Next step is to add new IAM user – go to https://console.aws.amazon.com/iam/home?#users, select Users and click Create new user button.
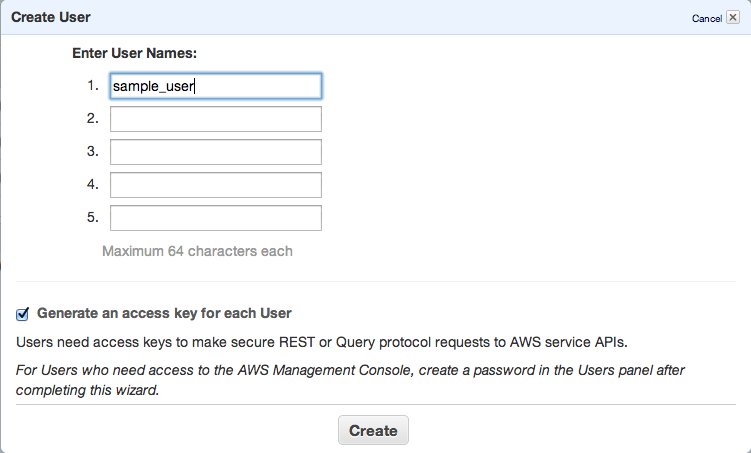
Click Create and copy/paste or download your access keys.
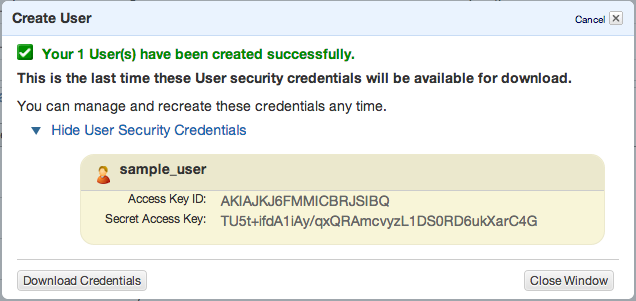
Then close window and click to summary tab – you’ll need to copy ARN notation of this user
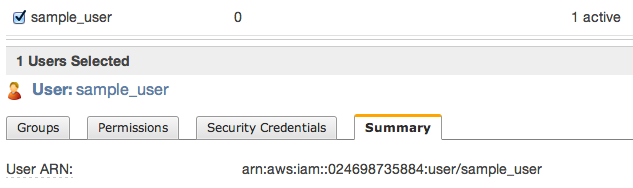
To be able to sync some folders and/or use s3cmd commandline tool, you need to setup some more policies. Click Permission tab and then Attach User Policy. Then choose Policy Generator and follow these steps:
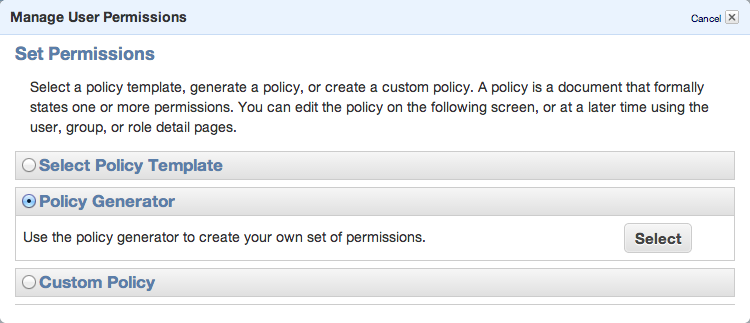 Set permissions as shown in following image – we need ListAllMyBuckets for :::* and ListBucket and PutObject for the one, specified bucket.
Set permissions as shown in following image – we need ListAllMyBuckets for :::* and ListBucket and PutObject for the one, specified bucket.
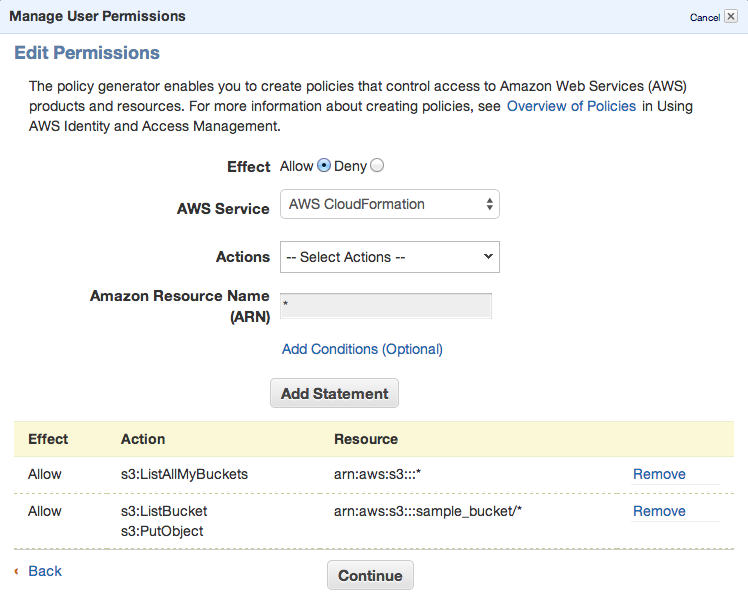
Click Continue and save new policy
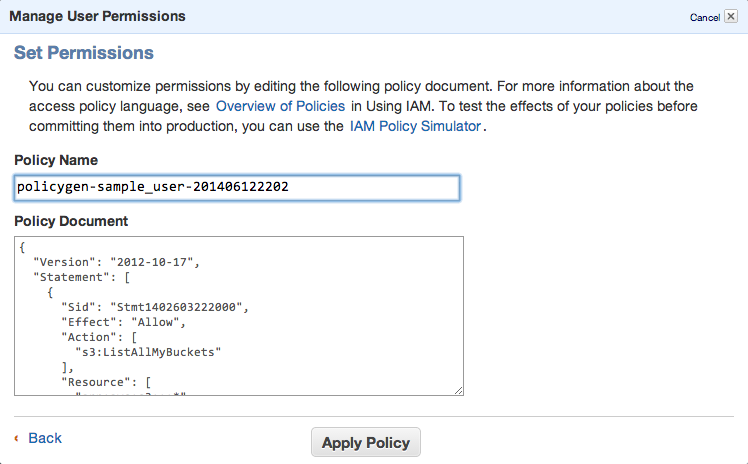
You can always edit the policy using Manage Policy. You should create this kind of policy file:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1402603222000",
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets"
],
"Resource": [
"arn:aws:s3:::*"
]
},
{
"Sid": "Stmt1402603306000",
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::sample_bucket/*"
]
}
]
}
That’s all. Lets move to bucket policy.
Now you can open Policy Generator – http://awspolicygen.s3.amazonaws.com/policygen.html and start adding new items.
First of all, select your policy type – S3

and then fill new policy – we need two policies – one for all users to read objects (GetObject) and second for your new user, to be able to upload, delete and get object as well.
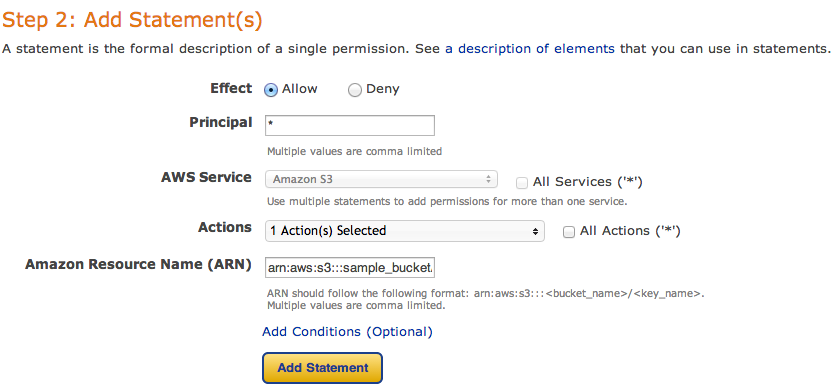
and click Add Statement. The list below the form should look like

So, add your user the same way. As principal add your ARN notation (which you copied before) and add Actions as shown below.

All set. You need to click Generate Policy button and copy freshly generated JSON policy to your clipboard
{
"Id": "Policy1402594421281",
"Statement": [
{
"Sid": "Stmt1402593998750",
"Action": [
"s3:GetObject"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::sample_bucket/*",
"Principal": {
"AWS": [
"*"
]
}
},
{
"Sid": "Stmt1402594323930",
"Action": [
"s3:AbortMultipartUpload",
"s3:DeleteObject",
"s3:GetObject",
"s3:GetObjectAcl",
"s3:PutObject",
"s3:PutObjectAcl"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::sample_bucket/*",
"Principal": {
"AWS": [
"arn:aws:iam::024698735884:user/sample_user"
]
}
}
]
}
Last step is to add this policy to the bucket. Go back to your S3 console (https://console.aws.amazon.com/s3/home), click loupe icon next to bucket name and open Permission section. Click on Edit Bucket Policy and paste the generated policy into that window. Save and you’re done.

You’ll need API keys for use with Paperclip or any other S3 storage engine, so keep them safe.
PS: when you plan to use s3 as storage for your static files, avoid using underscore in your bucket name – as it does not comply with valid FQDN. ‘sample_bucket’ was used only as an example, in the real word you should use ‘sample-bucket’.
Finally managed to get into AVR programming. Using OSX, which I found as the worst platform for doing any kind of embed programming :( Sad. Anyway, there’s my first ATtiny schematics and code. I’m using AVR Dragon to flash code into the MCU.
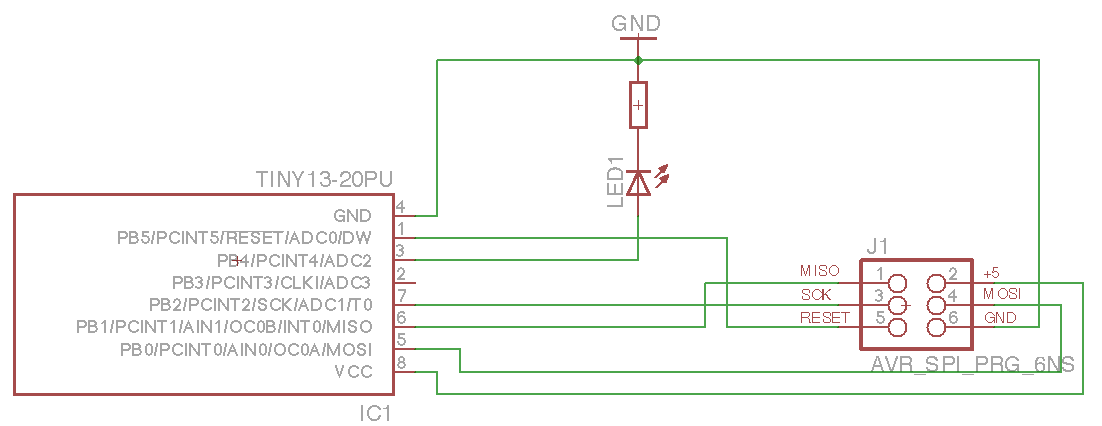
The circuit is quite simple. I just confirm SPI flashing works and I’m able to turn the LED on. So here’s some code (using avr-gcc to compile and avrdure to upload). Create new project using avr-project and add this to main.c file:
#include <avr/io.h>
#include <util/delay.h>
int main(void)
{
const int msDelay = 50;
// PortB pin4 to output (set bit to 1 using SHL)
DDRB = 1<<DDB4;
// PortB to low
PORTB = 0;
while (1) {
// XOR on pin 4
PORTB ^= 1<<PB4;
_delay_ms(msDelay);
}
return 0;
}
Now we can compile the firmware and upload to our MCU.
$ make avr-gcc -Wall -Os -DF_CPU=8000000 -mmcu=attiny13 -c main.c -o main.o avr-gcc -Wall -Os -DF_CPU=8000000 -mmcu=attiny13 -o main.elf main.o rm -f main.hex avr-objcopy -j .text -j .data -O ihex main.elf main.hex avr-size --format=avr --mcu=attiny13 main.elf AVR Memory Usage ---------------- Device: attiny13 Program: 72 bytes (7.0% Full) (.text + .data + .bootloader) Data: 0 bytes (0.0% Full) (.data + .bss + .noinit)
No errors. Great. Connect AVR Dragon and upload our new firmware:
$ make flash
avrdude -c dragon_isp -P usb -p attiny13 -U flash:w:main.hex:i
avrdude: AVR device initialized and ready to accept instructions
Reading | ################################################## | 100% 0.15s
avrdude: Device signature = 0x1e9007
avrdude: NOTE: "flash" memory has been specified, an erase cycle will be performed
To disable this feature, specify the -D option.
avrdude: erasing chip
avrdude: reading input file "main.hex"
avrdude: writing flash (110 bytes):
Writing | ################################################## | 100% 0.46s
avrdude: 110 bytes of flash written
avrdude: verifying flash memory against main.hex:
avrdude: load data flash data from input file main.hex:
avrdude: input file main.hex contains 110 bytes
avrdude: reading on-chip flash data:
Reading | ################################################## | 100% 0.47s
avrdude: verifying ...
avrdude: 110 bytes of flash verified
avrdude: safemode: Fuses OK (H:FF, E:FF, L:6A)
avrdude done. Thank you.

For those, interested in .hex file – this is how it looks like:
$ cat main.hex :1000000009C00EC00DC00CC00BC00AC009C008C09A :1000100007C006C011241FBECFE9CDBF02D012C059 :10002000EFCF80E187BB18BA90E188B3892788BBFE :100030002FE738E381E0215030408040E1F700C0F5 :080040000000F3CFF894FFCF9C :00000001FF
and I made some commented assembler output (base is taken from avr-objdump -S main.elf).
cat main.S main.elf: file format elf32-avr Disassembly of section .text: 00000000 <__vectors>: 0: 09 c0 rjmp .+18 ; 0x14 <__ctors_end> 2: 0e c0 rjmp .+28 ; 0x20 <__bad_interrupt> 4: 0d c0 rjmp .+26 ; 0x20 <__bad_interrupt> 6: 0c c0 rjmp .+24 ; 0x20 <__bad_interrupt> 8: 0b c0 rjmp .+22 ; 0x20 <__bad_interrupt> a: 0a c0 rjmp .+20 ; 0x20 <__bad_interrupt> c: 09 c0 rjmp .+18 ; 0x20 <__bad_interrupt> e: 08 c0 rjmp .+16 ; 0x20 <__bad_interrupt> 10: 07 c0 rjmp .+14 ; 0x20 <__bad_interrupt> 12: 06 c0 rjmp .+12 ; 0x20 <__bad_interrupt> 00000014 <__ctors_end>: ; set stack to SRAM 14: 11 24 eor r1, r1 ; set 0 to r1 16: 1f be out 0x3f, r1 ; 0 -> SPH 18: cf e9 ldi r28, 0x9F ; RAMEND 1a: cd bf out 0x3d, r28 ; r28 -> SPL 1c: 02 d0 rcall .+4 ; call main loop at 0x22 1e: 12 c0 rjmp .+36 ; then call exit at 0x44 00000020 <__bad_interrupt>: 20: ef cf rjmp .-34 ; 0x0 <__vectors> 00000022 <main>: 22: 80 e1 ldi r24, 0x10 ; 1<<DDB4 (0x10) -> r24 24: 87 bb out 0x17, r24 ; set r24 -> DDRB 26: 18 ba out 0x18, r1 ; set r1 (0) -> PORTB 28: 90 e1 ldi r25, 0x10 ; 1<<DDB4 2a: 88 b3 in r24, 0x18 ; read PORTB -> r24 to XOR 2c: 89 27 eor r24, r25 ; XOR pin 4 2e: 88 bb out 0x18, r24 ; set r24 -> PORTB 30: 2f e7 ldi r18, 0x7F ; 0x01387f = wait 79999 ticks (50ms at 4MHz) 32: 38 e3 ldi r19, 0x38 ; 34: 81 e0 ldi r24, 0x01 ; 36: 21 50 subi r18, 0x01 ; decrease r18 by 1 38: 30 40 sbci r19, 0x00 ; and decrease other by carry bit 3a: 80 40 sbci r24, 0x00 ; 3c: e1 f7 brne .-8 ; repeat until zero set - jump to 0x36 3e: 00 c0 rjmp .+0 ; relative jump to 0x40 40: 00 00 nop ; do nothing 42: f3 cf rjmp .-26 ; jump back to 0x2a (loop) 00000044 <_exit>: 44: f8 94 cli 00000046 <__stop_program>: 46: ff cf rjmp .-2 ; 0x46 <__stop_program>
We’re currently using (for one part of our infrastructure) logging into elasticsearch. We have fluentd collectors and kibana interface for viewing and searching through the logs. 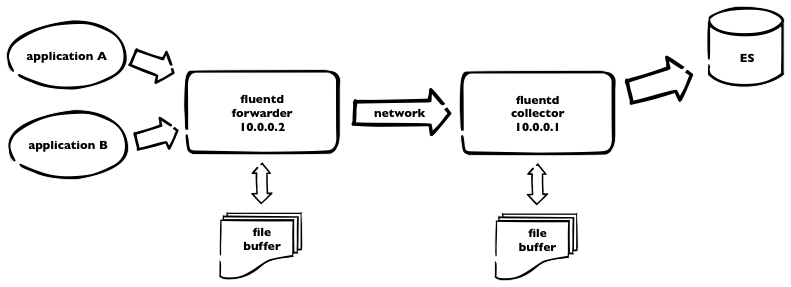 This is how it works. Logs are sent to fluentd forwarder and then over the network to fluentd collector, which pushes all the logs to elasticsearch. As we have plenty of logs, we need to incorporate some buffering – on both sides – using buffer_file statement in the fluentd config. Here is a part of our fluentd config from forwarder
This is how it works. Logs are sent to fluentd forwarder and then over the network to fluentd collector, which pushes all the logs to elasticsearch. As we have plenty of logs, we need to incorporate some buffering – on both sides – using buffer_file statement in the fluentd config. Here is a part of our fluentd config from forwarder
<match ***>
type forward
send_timeout 60s
recover_wait 10s
heartbeat_interval 1s
phi_threshold 16
hard_timeout 120s
# buffer
buffer_type file
buffer_path /opt/fluentd/buffer/
buffer_chunk_limit 8m
buffer_queue_limit 4096
flush_interval 10s
retry_wait 20s
# log to es
<server>
host 10.0.0.1
</server>
<secondary>
type file
path /opt/fluentd/failed/
</secondary>
</match>
and the same for the collector
<source> type forward bind 10.0.0.1 </source> <match log.**> type elasticsearch logstash_format true # elastic host host 10.0.0.3 port 9200 logstash_prefix log include_tag_key # buffering buffer_type file buffer_path /opt/fluentd/buffer/ flush_interval 5m buffer_chunk_limit 16m buffer_queue_limit 4096 retry_wait 15s </match>
So. For the forwarder, we’re using buffer with max 4096 8MB chunks = 32GB of buffer space. Forwarder is flushing every 10secs. For collector, we use bigger chunks, as elasticsearch is capable to handle it – but not using default 256MB chunks due to memory limitations. Flushing period is longer – and should be – recommended value is 5minutes. We can keep up to 64Gigs of buffer data.
What happens if one of the fluentd dies. Some data will be probably lost, when unsaved to buffer. But. When there’s connection lost or collector fluentd isn’t running, all logs, collected by forwarder, are stored into the buffer – and sent later. Which is great. The same when ES is down for some reason, collector node is still receiving data and is able to continue sending into ES after full recovery.
PS: don’t forget to make some tweaks to the system itself, like raise the limit for max files opened and some tcp tunning.
After some successful setup of Kibana + es for fluentd there’s a need to secure whole website. So I decided to use nginx and basic auth. I assume you have standard configuration – with es running on localhost:9200.
# htpasswd -c /opt/nginx/conf/.htpasswd some_user
and now modify nginx config:
#user nobody;
#group nogroup;
worker_processes 5;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
sendfile on;
keepalive_timeout 65;
gzip on;
server {
# we listen on :8080
listen 8080;
server_name somer.server;
charset utf-8;
access_log logs/host.access.log main;
# root for Kibana installation
location / {
auth_basic "Restricted";
auth_basic_user_file /opt/nginx/conf/.htpasswd;
root /opt/kibana;
index index.html index.htm;
}
# and for elasticsearch
location /es {
auth_basic "Restricted - ES";
auth_basic_user_file /opt/nginx/conf/.htpasswd;
rewrite ^/es/_aliases$ /_aliases break;
rewrite ^/es/_nodes$ /_nodes break;
rewrite ^/es/(.*/_search)$ /$1 break;
rewrite ^/es/(.*/_mapping)$ /$1 break;
rewrite ^/es/(.*/_aliases)$ /$1 break;
rewrite ^/es/(kibana-int/.*)$ /$1 break;
return 403;
# set some headers
proxy_http_version 1.1;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_pass http://localhost:9200;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
Booom! After reinstall of one of our servers I got into this. Weird error. It’s caused by paramiko. There’s no code fix available, but reason is simple – and fix too.
Connect to your box, and simply remove two files from /etc/ssh directory
root@limone:/# ls -la /etc/ssh/ total 168 drwxr-xr-x 2 root root 4096 Apr 24 15:31 . drwxr-xr-x 82 root root 4096 Apr 24 16:00 .. -rw-r--r-- 1 root root 136156 Feb 8 2013 moduli -rw-r--r-- 1 root root 1669 Feb 8 2013 ssh_config -rw------- 1 root root 668 Apr 23 12:05 ssh_host_dsa_key -rw-r--r-- 1 root root 601 Apr 23 12:05 ssh_host_dsa_key.pub -rw------- 1 root root 227 Apr 23 12:05 ssh_host_ecdsa_key -rw-r--r-- 1 root root 173 Apr 23 12:05 ssh_host_ecdsa_key.pub -rw------- 1 root root 1675 Apr 23 12:05 ssh_host_rsa_key -rw-r--r-- 1 root root 393 Apr 23 12:05 ssh_host_rsa_key.pub -rw-r--r-- 1 root root 2510 Apr 23 12:15 sshd_config
so, remove these two files:
-rw------- 1 root root 227 Apr 23 12:05 ssh_host_ecdsa_key -rw-r--r-- 1 root root 173 Apr 23 12:05 ssh_host_ecdsa_key.pub
Then clean up ~/.ssh/known_hosts file on the box your’re running backup from
ssh-keygen -f "/root/.ssh/known_hosts" -R server_fqdn ssh-keygen -f "/root/.ssh/known_hosts" -R server_ip
connect using ssh to backup server from that host (to write id_rsa keys into known_hosts file)
# ssh root@server_fqdn Warning: the RSA host key for 'server_fqdn' differs from the key for the IP address 'server_ip' Offending key for IP in /root/.ssh/known_hosts:3 Matching host key in /root/.ssh/known_hosts:11 Are you sure you want to continue connecting (yes/no)? yes root@server_fqdn's password:
and run duplicate again.
voila! :)
Bílky vyšlehat na sníh, cukr utřít se žloutky, přidat zbytek. Pečeme při 160oC cca hodinu (3,5kW – cca 10Kč). Aby dort byl plochý, můžeme překlopit vzhůru nohama na podložku.
Čas přípravy – 30min (50Kč), cena za korpus – 44,60 + 50Kč = 94,60 Kč
ad korpus I – místo kakaa drcené ořechy, pár kapek vanilkového aroma. Cena cca 115 Kč.
Máslo nechat povolit, aby mělo pokojovou teplotu. V kastrůlku mléko, pudink, cukr, projít varem. Ve studené lázni vymíchat – dokud to nepálí. Pak postupně zašleháme máslo. Přidal jsem i půl víčka rumu. Dát vychladit do lednice.
Čas: 30minut, cena 135Kč + 50Kč práce – 185 Kč
Smetanu vyšlehat se ztužovačem, pak vše ostatní smíchat a vymíchat dohladka.
Čas: 30minut, cena 136Kč + 50Kč práce – 186 Kč
Na dort je třeba také potahovací hmota – té bylo čtyřnásobek množství v tomto postu. Cena tedy 4x30Kč + cca 20minut práce – 34Kč – celkem za potahovací hmotu 154Kč
Náklady na dort jsou tedy celkem 735Kč.








Můj první pokus – peču dort. Chtěl jsem potahovat, takže jsem v Makru omylem zakoupil Fondánovou hmotu – od Kovandy. Kyblík 4kg – mají i menší balení. Na kyblíku je napsáno, že pokud z toho má být potahovací hmota, je třeba to smíchat se sušeným mlékem, olejem atd.. Takže jsem zkusil internet, našel pár “recepisů” a interpoloval. Výsledek docela překvapil, na to, že to bylo poprvé :-)

Ingredience:
Hmotu, cukr a mléko jsem dal do misky, v mikrovlnce prohřál chvilku – hmota se částečně rozpustí. Přidal jsem vše ostatní. Je potřeba si připravit misku s vlažnou vodou, na namáčení rukou. Ingredience mícháme – nebojte se, zůstává to dlouho sypké, je treba to mačkat mezi prsty – asi jako když se dělají bramb. knedlíky. Postupně namáčíme ruce do vody – já namáčel asi 3x – tady pozor – voda se nepřidává – přemokřený “marcipán” nejde nastavit. Je třeba hníst do doby, než hmota bude jednolitá – můžeme si pomoci hnětením na desce, podsypáváme škrobem. Následně do pytlíku, dobře uzavřít. Dá se dobře barvit gelovými barvami – pokud třeba ředit, ředíme alkoholem.
Čas: cca 10minut, cena cca 30 Kč + 17 Kč práce – 47 Kč
As I’m building my own IQ house control system, I need to have RTC in my system. So started playing with MCP7940N and i2c interface. I’m using Raspberry Pi for my experiments with i2c/SPI.
Construction is pretty simple, just use MCP7840N Datasheet.
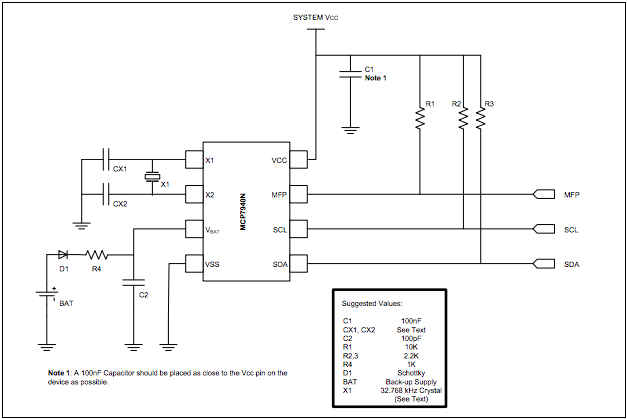
Then you can start checking with Pi. In my case, I’m using RevB, so my bus has number 1 and RTC got 0x6f address.
root@pi:~# i2cdetect -y 1
0 1 2 3 4 5 6 7 8 9 a b c d e f
00: -- -- -- -- -- -- -- -- -- -- -- -- --
10: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
20: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
30: -- -- -- -- -- -- -- -- -- -- -- UU -- -- -- --
40: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
50: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
60: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 6f
70: -- -- -- -- -- -- -- --
what next? Check address 0x00, if the onboard oscilator is running
root@pi:~# i2cget -y 1 0x6f 0x00 b 0x00
0x00 means NO, it’s NOT running. So, turn it on
root@pi:~# i2cset -y1 1 0x6f 0x00 0x80
and check few times address 0x00
root@pi:~# i2cget -y 1 0x6f 0x00 b 0x87 root@pi:~# i2cget -y 1 0x6f 0x00 b 0x88 root@pi:~# i2cget -y 1 0x6f 0x00 b 0x89 root@pi:~# i2cget -y 1 0x6f 0x00 b 0x90 root@pi:~# i2cget -y 1 0x6f 0x00 b 0x91
Increments! Great. That means – our oscilator is working = our clock is working too. Next step is to set current time and date. But wait. How are values stored and read/written? RTC uses BCD encoding for values, that means, eg. number 94 is stored as 9 and 4, both in 4 bits = 9 is stored as 1001 and 4 as 0100, in hexadecimal 0x94. Easy? Eg. day is using 6 bits, upper two for 0123 values, bottom bits for 0-9, so 31th will be stored as 0x31. For more details please read the PDF – RTCC Memory map. So back to setting the date & time:
# 2nd Feb 2014 root@pi:~# i2cset -y 1 0x6f 0x06 0x14 root@pi:~# i2cset -y 1 0x6f 0x05 0x02 root@pi:~# i2cset -y 1 0x6f 0x04 0x19 # 00:02:00 root@pi:~# i2cset -y 1 0x6f 0x02 0x00 root@pi:~# i2cset -y 1 0x6f 0x01 0x02 root@pi:~# i2cset -y 1 0x6f 0x01 0x80
Fine. But if we’re setting ’00’ as seconds – address 0x00 – why value 0x80? 7th bit = ST – onboard oscilator enabled.
I’ve written simple Python code to read from RTC and print out the value:
from time import sleep
import smbus
import time
import signal
import sys
bus = smbus.SMBus(1)
RTC_ADDR = 0x6f
ADDR_SEC = 0x00
ADDR_MIN = 0x01
ADDR_HOUR = 0x02
def signal_handler(signal, frame):
sys.exit(0)
def bcd2bin(x):
return (((x) & 0x0f) + ((x) >> 4) * 10)
if __name__ == "__main__":
signal.signal(signal.SIGINT, signal_handler)
while True:
sec = bcd2bin(bus.read_byte_data(RTC_ADDR, ADDR_SEC) & 0x7f)
min = bcd2bin(bus.read_byte_data(RTC_ADDR, ADDR_MIN) & 0x7f)
hour = bcd2bin(bus.read_byte_data(RTC_ADDR, ADDR_HOUR) & 0x3f)
print "%02d:%02d:%02d" % (hour, min, sec)
sleep(0.9) # nearly 1 sec
Just run by
root@pi:~# python rtc.py 00:35:41 00:35:42 00:35:43 00:35:44 00:35:45 00:35:46
Voila! :) RTC is up and running. I’d like to check tomorrow (resp. today) morning, if everything is still working correctly, and can create next module for my IQ house control system :)
I need to setup deploy task to run eye. Tried to deal with gem-wrappers, but had no success. As capistrano3 is using non-interactive ssh, without loading user’s environment (.profile, .bashrc etc), then command, which is not in PATH, it’s not workin.
So, after searching and reading capistrano (capistrano/rvm) source, then sshkit source, I got into this simple solution.
It’s not dependent on any other settings nor knowing what, where rvm is installed.
before change in deploy.rb (not working)
INFO [57a66442] Running /usr/bin/env eye info on example.com DEBUG [46484690] Command: cd /home/deploy/app/releases/20140130214109 && ( /usr/bin/env eye info ) DEBUG [46484690] /usr/bin/env: eye DEBUG [46484690] : No such file or directory
after change in deploy.rb
INFO [a2f9c75f] Running /usr/local/rvm/bin/rvm default do eye info on example.com
set :rvm_remap_bins, %w{eye}
namespace :settings do
task :prefix_rake do
fetch(:rvm_remap_bins).each do |cmd|
SSHKit.config.command_map[cmd.to_sym] = "#{SSHKit.config.command_map[:gem].gsub(/gem$/,'')} #{cmd}"
end
end
end
after 'rvm:hook', 'settings:prefix_rake'
original code from capistrano is
# https://github.com/capistrano/rvm/blob/master/lib/capistrano/tasks/rvm.rake
SSHKit.config.command_map[:rvm] = "#{fetch(:rvm_path)}/bin/rvm"
rvm_prefix = "#{fetch(:rvm_path)}/bin/rvm #{fetch(:rvm_ruby_version)} do"
fetch(:rvm_map_bins).each do |command|
SSHKit.config.command_map.prefix[command.to_sym].unshift(rvm_prefix)
end
...
set :rvm_map_bins, %w{gem rake ruby bundle}