Dostal jsem pověření z nejvyšších míst vyrobit statistické zhodnocení dotazníků. A protože bytostně nemám rád Excel, našel jsem R a zkouším.
Udělal jsem data do CSV souboru a nahrál do R (RStudio)
> head(dotaznik.csv)
num type gender age height weight edu
1 1 H M 60 182 100 Vysokoškolské
2 2 H M 49 188 102 Vyučen/a
3 3 H M 61 176 75 Vyučen/a
4 4 H M 56 180 110 Střední
5 5 H M 47 180 95 Vysokoškolské
6 6 H M 48 178 95 Střední
Zkusíme vyrobit četnost vzdělání (edu) a potom ji ještě rozdělit podle pohlaví (gender).
> edu <- table(dotaznik.csv$edu)
> edu
Střední Vysokoškolské Vyšší odborné Vyučen/a
30 7 2 25
Základní
6
Máme tabulku, ale potřebujeme z ní frame
> fedu <- as.data.frame(edu)
> fedu
Var1 Freq
1 Střední 30
2 Vysokoškolské 7
3 Vyšší odborné 2
4 Vyučen/a 25
5 Základní 6
Přidáme relativní četnost (mean)
> fedu$mean <- fedu$Freq / sum(fedu$Freq)
> fedu
Var1 Freq mean
1 Střední 30 0.42857143
2 Vysokoškolské 7 0.10000000
3 Vyšší odborné 2 0.02857143
4 Vyučen/a 25 0.35714286
5 Základní 6 0.08571429
A teď na graf. Používáme ggplot2.
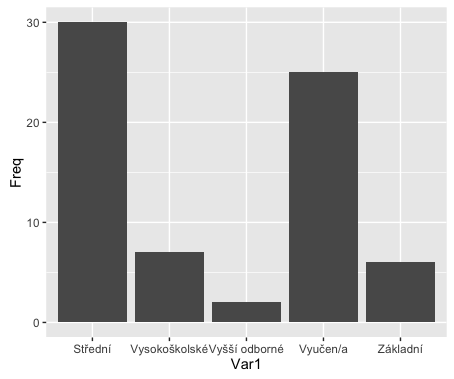
ggplot(fedu, aes(x=Var1, y=Freq)) + geom_bar(stat='identity')
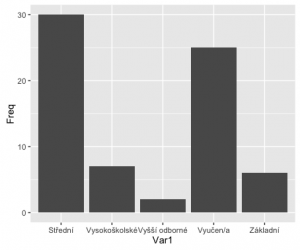
Fajn. Ale chceme graf otočit
ggplot(fedu, aes(x=Var1, y=Freq)) + geom_bar(stat='identity') + coord_flip()
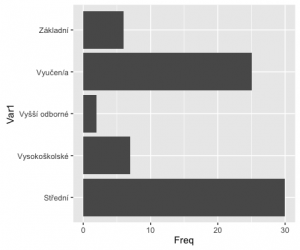
Teď ještě smazat popisek osy x a přepsat osu y.
ggplot(fedu, aes(x=Var1, y=Freq)) + geom_bar(stat='identity') +
coord_flip() +
xlab('Vzdělání') +
theme(axis.title.x = element_blank()) +
ggtitle('Dosažené vzdělání')
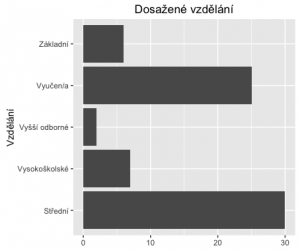
A finálně přidáme hodnoty frekvence do jednotlivých sloupců.
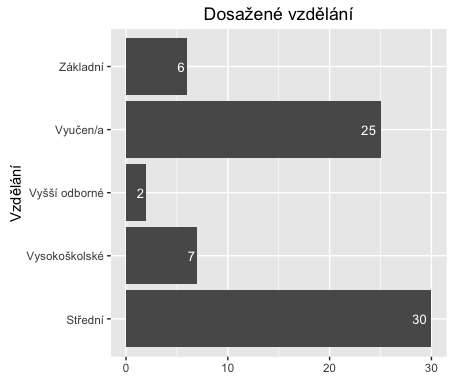
ggplot(fedu, aes(x=Var1, y=Freq)) +
geom_bar(stat='identity', position=position_dodge()) +
geom_text(aes(label=Freq), hjust=1.3, color="white",position = position_dodge(0.9), size=3.5) +
coord_flip() +
xlab('Vzdělání') +
theme(axis.title.x = element_blank()) +
ggtitle('Dosažené vzdělání')
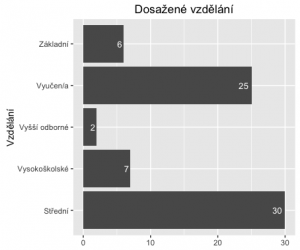
A teď trochu komplexněji. Ještě to rozdělíme na muže a ženy..
> edu <- table(dotaznik.csv$gender, dotaznik.csv$edu)
> edu
Střední Vysokoškolské Vyšší odborné Vyučen/a Základní
M 10 4 2 17 1
Ž 20 3 0 8 5
> fedu <- as.data.frame(edu)
> fedu
Var1 Var2 Freq
1 M Střední 10
2 Ž Střední 20
3 M Vysokoškolské 4
4 Ž Vysokoškolské 3
5 M Vyšší odborné 2
6 Ž Vyšší odborné 0
7 M Vyučen/a 17
8 Ž Vyučen/a 8
9 M Základní 1
10 Ž Základní 5
a přidáme graf
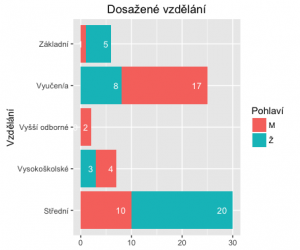
> ggplot(fedu, aes(x=Var2, y=Freq, fill=Var1)) +
geom_bar(stat='identity', position=position_dodge()) +
geom_text(aes(label=Freq), hjust=1.6, color="white",position = position_dodge(0.9), size=3.5) +
coord_flip() +
xlab('Vzdělání') +
theme(axis.title.x = element_blank()) +
ggtitle('Dosažené vzdělání') +
labs(fill = 'Pohlaví')
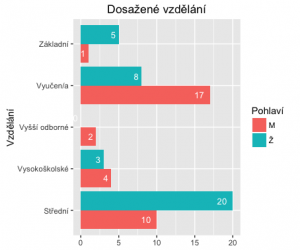
A co když budeme chtít jeden bar, ale rozdělený podle hodnot?
# seridime podle Var2 a Freq
> library(plyr)
> fedu_s <- arrange(fedu, Var2, Freq)
> fedu_s
Var1 Var2 Freq
1 M Střední 10
2 Ž Střední 20
3 Ž Vysokoškolské 3
4 M Vysokoškolské 4
5 Ž Vyšší odborné 0
6 M Vyšší odborné 2
7 Ž Vyučen/a 8
8 M Vyučen/a 17
9 M Základní 1
10 Ž Základní 5
# a pridame souhrnny soucet, rozdeleny s kazdym jinym Var2
> fedu_s_sum <- ddply(fedu_s, 'Var2', transform, label_ypos=cumsum(Freq))
> fedu_s_sum
Var1 Var2 Freq label_ypos
1 M Střední 10 10
2 Ž Střední 20 30
3 Ž Vysokoškolské 3 3
4 M Vysokoškolské 4 7
5 Ž Vyšší odborné 0 0
6 M Vyšší odborné 2 2
7 Ž Vyučen/a 8 8
8 M Vyučen/a 17 25
9 M Základní 1 1
10 Ž Základní 5 6
A graf
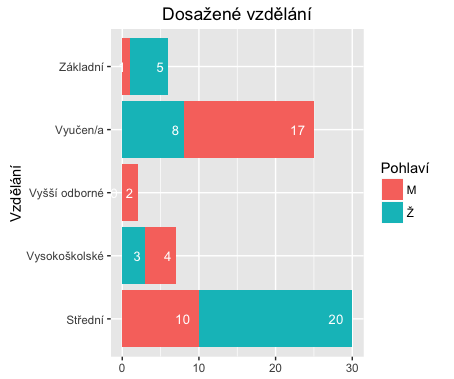
ggplot(fedu_s_sum, aes(x=Var2, y=Freq, fill=Var1)) +
geom_bar(stat='identity') +
geom_text(aes(label=Freq, y=label_ypos), hjust=1.6, color="white", size=3.5) +
coord_flip() +
xlab('Vzdělání') +
theme(axis.title.x = element_blank()) +
ggtitle('Dosažené vzdělání') +
labs(fill = 'Pohlaví')