We’re currently using (for one part of our infrastructure) logging into elasticsearch. We have fluentd collectors and kibana interface for viewing and searching through the logs. 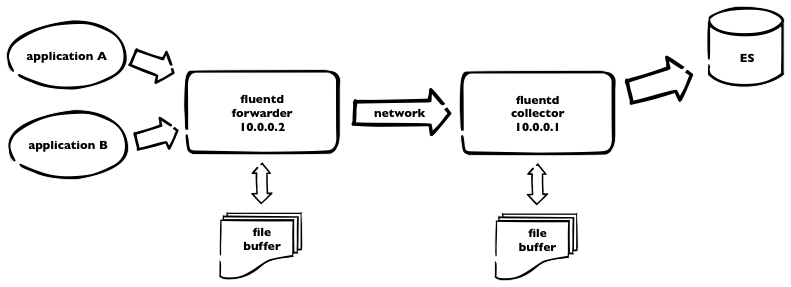 This is how it works. Logs are sent to fluentd forwarder and then over the network to fluentd collector, which pushes all the logs to elasticsearch. As we have plenty of logs, we need to incorporate some buffering – on both sides – using buffer_file statement in the fluentd config. Here is a part of our fluentd config from forwarder
This is how it works. Logs are sent to fluentd forwarder and then over the network to fluentd collector, which pushes all the logs to elasticsearch. As we have plenty of logs, we need to incorporate some buffering – on both sides – using buffer_file statement in the fluentd config. Here is a part of our fluentd config from forwarder
<match ***>
type forward
send_timeout 60s
recover_wait 10s
heartbeat_interval 1s
phi_threshold 16
hard_timeout 120s
# buffer
buffer_type file
buffer_path /opt/fluentd/buffer/
buffer_chunk_limit 8m
buffer_queue_limit 4096
flush_interval 10s
retry_wait 20s
# log to es
<server>
host 10.0.0.1
</server>
<secondary>
type file
path /opt/fluentd/failed/
</secondary>
</match>
and the same for the collector
<source> type forward bind 10.0.0.1 </source> <match log.**> type elasticsearch logstash_format true # elastic host host 10.0.0.3 port 9200 logstash_prefix log include_tag_key # buffering buffer_type file buffer_path /opt/fluentd/buffer/ flush_interval 5m buffer_chunk_limit 16m buffer_queue_limit 4096 retry_wait 15s </match>
So. For the forwarder, we’re using buffer with max 4096 8MB chunks = 32GB of buffer space. Forwarder is flushing every 10secs. For collector, we use bigger chunks, as elasticsearch is capable to handle it – but not using default 256MB chunks due to memory limitations. Flushing period is longer – and should be – recommended value is 5minutes. We can keep up to 64Gigs of buffer data.
What happens if one of the fluentd dies. Some data will be probably lost, when unsaved to buffer. But. When there’s connection lost or collector fluentd isn’t running, all logs, collected by forwarder, are stored into the buffer – and sent later. Which is great. The same when ES is down for some reason, collector node is still receiving data and is able to continue sending into ES after full recovery.
PS: don’t forget to make some tweaks to the system itself, like raise the limit for max files opened and some tcp tunning.
hey how flush_interval field used, because in my knowledge logs goes to buffer only if the collector goes down, so how flush_interval 5m related